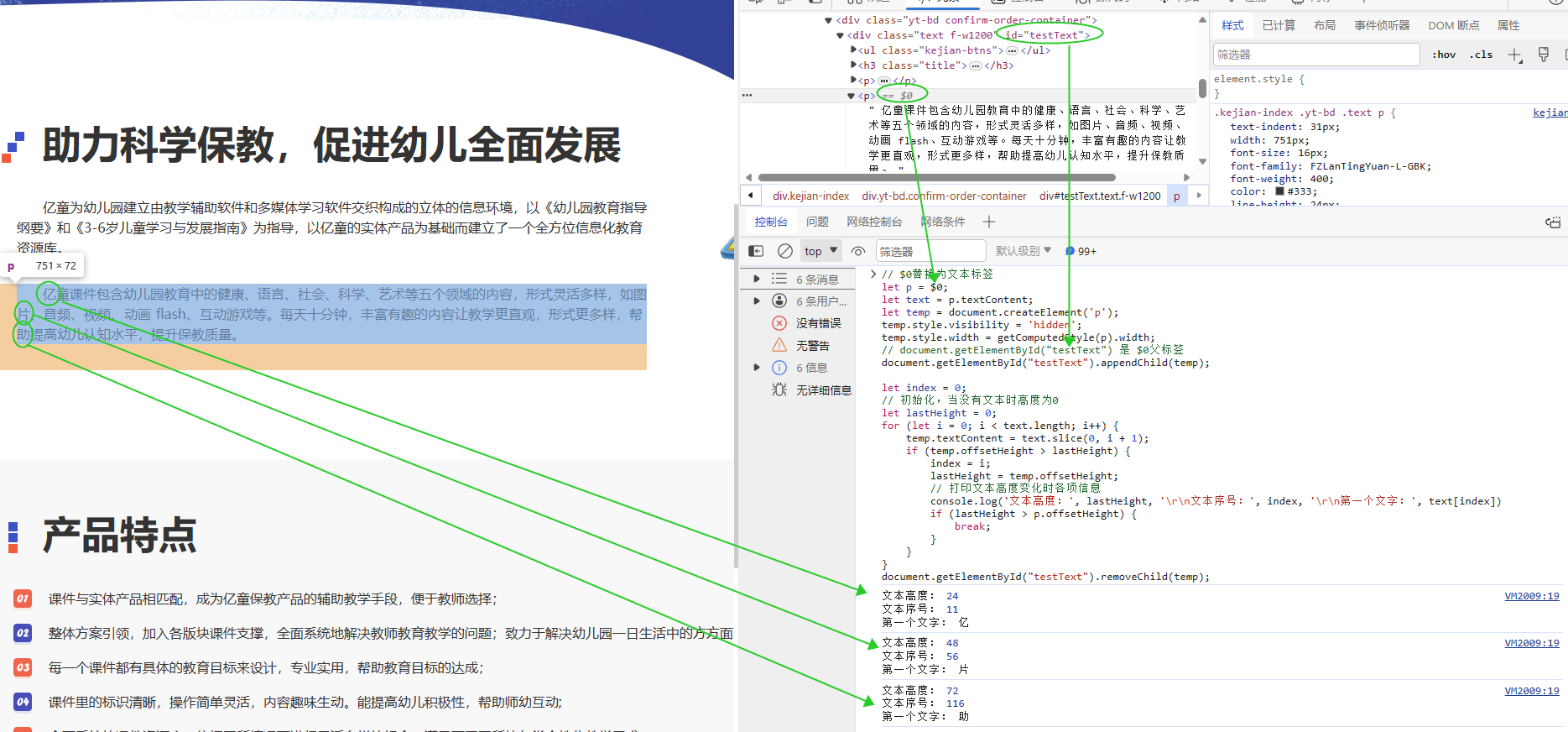
在前端排版、文本高亮、行号标注等场景中,我们经常需要动态计算一段文本在自动换行后,每一行第一个文字的索引位置。
核心思路是:克隆一个与原始节点样式完全一致的隐藏临时节点,通过逐个追加文本并监听高度变化,来精准捕捉每次换行的临界点。
优化后的完整实现
核心函数封装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
function getLineBreakIndices(originalElement) {
if (!originalElement || !originalElement.textContent) {
return [];
}
const text = originalElement.textContent;
const lineBreakIndices = [];
const tempElement = originalElement.cloneNode(true);
tempElement.style.visibility = 'hidden';
tempElement.style.position = 'absolute';
tempElement.style.top = '-9999px';
tempElement.style.left = '-9999px';
tempElement.style.pointerEvents = 'none';
tempElement.textContent = '';
const parentContainer = originalElement.parentNode;
parentContainer.appendChild(tempElement);
let previousHeight = 0;
for (let i = 0; i < text.length; i++) {
tempElement.textContent = text.slice(0, i + 1);
const currentHeight = tempElement.offsetHeight;
if (currentHeight > previousHeight) {
lineBreakIndices.push(i);
previousHeight = currentHeight;
console.log(
`第 ${lineBreakIndices.length} 行首字:`,
`索引 = ${i}`,
`字符 = "${text[i]}"`,
`当前高度 = ${currentHeight}px`
);
}
}
parentContainer.removeChild(tempElement);
return lineBreakIndices;
}
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<div id="textContainer">
<p id="targetText" class="content-text" style="width: 300px; font-size: 16px; line-height: 1.8;">
这是一段很长的文本,用来测试动态计算换行首字索引的功能。当文本宽度不够时,它会自动换行,我们需要找到每一行第一个字的位置。
</p>
</div>
<script>
const textElement = document.getElementById('targetText');
const indices = getLineBreakIndices(textElement);
console.log('所有换行首字索引:', indices);
const text = textElement.textContent;
indices.forEach((startIndex, lineIndex) => {
const endIndex = indices[lineIndex + 1] || text.length;
const lineContent = text.slice(startIndex, endIndex);
console.log(`第 ${lineIndex + 1} 行内容:`, lineContent);
});
</script>
|
关键优化点说明
1. 使用 cloneNode(true) 替代 createElement
这是最核心的优化。原代码中通过 createElement('p') 创建临时节点,需要手动复制样式,极易因遗漏 class、line-height、font-size、padding 等属性导致计算错位。
使用 originalElement.cloneNode(true) 可以:
- 完美保留原始节点的标签类型、所有
class、内联 style;
- 继承相同的 CSS 规则(受父容器影响的样式也能保持一致);
- 确保文本渲染的行高、字间距与原始节点完全一致。
2. 优化临时节点的隐藏方式
原代码仅设置了 visibility: hidden,优化后增加了:
position: absolute + top/left: -9999px:将节点移出视口,完全不占用页面文档流空间;pointerEvents: none:避免临时节点拦截鼠标事件。
3. 结果存储为数组
原代码仅记录了最后一次换行的索引,优化后将所有换行首字索引存入数组 lineBreakIndices,可支持多行文本的完整解析。
4. 动态获取父容器
原代码硬编码了 document.getElementById("testText"),优化后通过 originalElement.parentNode 动态获取,函数通用性更强。
注意事项
- 确保原始节点已渲染完成:需在
DOMContentLoaded 或 window.onload 之后调用,或确保节点已插入文档流且样式已计算,否则 offsetHeight 可能为 0。
- 处理富文本场景:如果原始节点包含
<br>、<span> 等子元素,需先将其转换为纯文本,或调整逻辑以支持子节点解析。
- 性能考虑:对于超长文本(如超过 10000 字),逐个字符追加可能会有性能损耗,可考虑按“词”或“句”批量追加,再在临界点附近回退到单字符检测。
原理解析
- 布局上下文一致性:临时节点必须插入到与原始节点相同的父容器中,才能确保
width、max-width、word-wrap 等布局属性的计算结果一致。
- 高度变化判定:当文本从
n 个字符增加到 n+1 个字符时,如果 offsetHeight 增加,说明第 n+1 个字符触发了换行,因此 n+1 即为新一行的首字索引(注意:第一行首字索引为 0)。